从上下文崩溃到主动系统巩固:AI为什么需要「睡眠」机制
2026年3月,Anthropic的一次意外打包失误,将ClaudeCode的51万行源代码暴露在npm公共仓库中。几个小时后,这些代码被完整镜像至GitHub,再也无法撤回。在这批泄露代码中,autoDream(自动做梦)模块引发了广泛讨论——这个名字本身就足够耐人寻味。
autoDream是KAIROS系统的核心组件,后者在用户工作期间持续观察记录,而autoDream仅在用户关闭电脑后启动,负责整理日间积累的记忆、消除矛盾、将模糊观察转化为确定事实。两套机制构成了完整的作息周期:KAIROS醒着,autoDream睡着。Anthropic的工程师们为AI造了一套作息表。
过去两年,Agent(自主代理)是最热的行业叙事。永不停机、持续运行,被视为AI相对于人类的核心优势。但将Agent能力推得最深的公司,反而在自己的代码里设置了休息时间。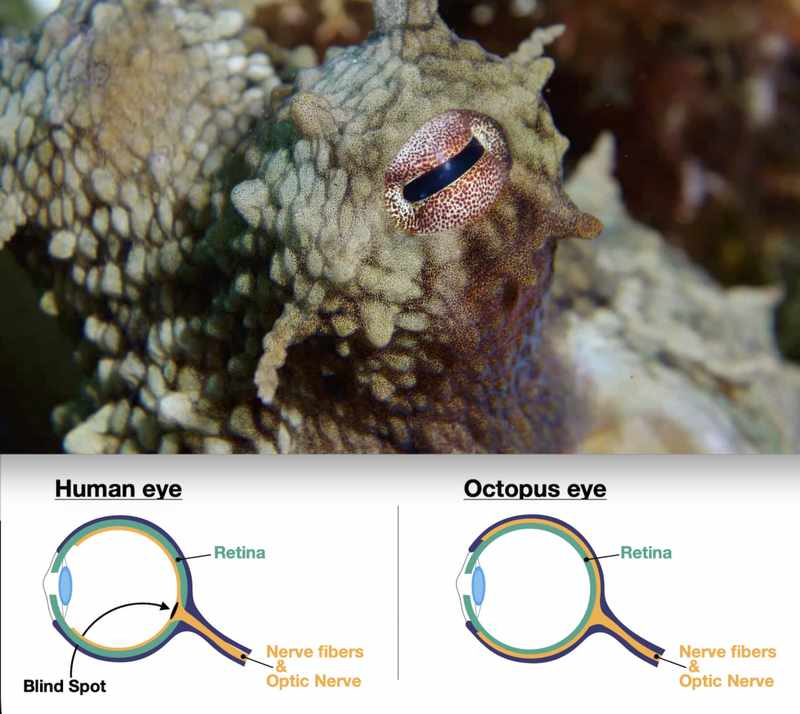
上下文窗口的硬边界
每个大语言模型都有上下文窗口限制,同一时刻能处理的信息总量存在物理上限。当Agent持续运行时,项目历史、用户偏好、对话记录不断堆积,超过临界点后,模型开始遗忘早期指令、前后矛盾、编造事实。技术社区将此称为「上下文腐化」。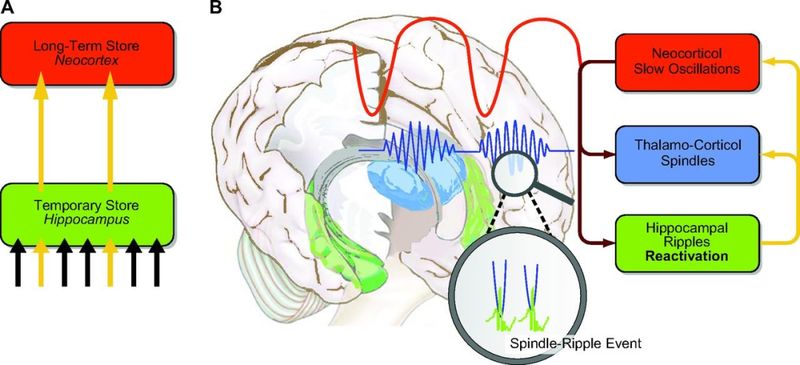
许多Agent的应对策略简单粗暴:将所有历史塞进上下文窗口,指望模型自己分清主次。讽刺的是,信息越多,表现越差。这堵墙,人脑同样撞过。
趋同进化下的两种答案
生物学中有一个概念叫趋同进化:亲缘关系很远的物种,因为面对相似的环境压力,会独立演化出相似的解决方案。最经典的例子是眼睛——章鱼和人类的相机式眼睛,结构几乎完全一致,但两者在五亿多年前拥有共同祖先时,地球上还没有任何复杂视觉器官。两条完全独立的演化路线走向相同终点,因为物理规律允许的路径几乎只有一种。
autoDream和人脑睡眠之间,可能就是这一类:在相似约束下,两类系统收敛到相似结构。
关键共同点在于「必须离线」。autoDream以分叉子进程独立启动,与主线程完全隔离。人脑的解决方案更为彻底——记忆从海马体(临时存储区)转移至新皮层(长期存储区),需要一组只在睡眠中才会出现的脑电节律:海马体的尖波涟漪负责打包记忆片段,大脑皮层的慢振荡和丘脑的纺锤波提供精确时序配合。这套节律在清醒状态下无法形成,外部刺激会破坏整个过程。
编辑而非全量记录
两个系统做出了相似的第二个选择:不做全量记忆,做编辑。autoDream启动后不会保留所有日志,而是重点处理与此前认知有偏差的部分——那些跟之前说的不一样的、比预期更复杂的记忆,优先记下。整理后的记忆建立三层索引:轻量指针层始终加载,主题文件按需调入,完整历史永远不直接加载。
人脑几乎在做同样的事。哈佛医学院研究表明,睡眠优先巩固不寻常的信息:令人意外的、引发情绪波动的、与待解决问题相关的。大量重复、无特征的日常细节被丢弃,只留下抽象规律。
但有一个差异值得注意:autoDream产出的记忆被标注为「hint」(线索)而非「truth」(真相),每次使用前都需要重新验证。这源于一个核心认知——它知道自己整理的东西可能不准。人脑没有这套机制,法庭上的目击证人常给出错误证词,正是因为记忆是从零散碎片临时拼凑的。
智能的基本开销
趋同进化意味着两条独立路线在没有直接信息交换的情况下走向相同终点。大自然没有抄袭,但工程师可以看论文。Anthropic在设计睡眠机制时,到底是因为撞上了和人脑一样的物理墙,还是从一开始就参考了脑科学?从泄露代码来看,没有任何神经科学文献引用,autoDream这个名字更接近程序员的玩笑。更有力的驱动应该是工程约束本身——上下文有硬上限,长时间运行导致噪音累积,在线整理会污染主线程推理。
真正决定答案形状的,还是约束本身的压缩力。过去两年,AI行业对「更强智能」的定义指向同一方向:更大的模型、更长的上下文、更快的推理、7×24小时不间断运行。方向永远是「更多」。autoDream的存在暗示了一个不同命题:聪明的智能体,可能是更懒惰的智能体。一个从不停下来整理自己的智能体,不会变得越来越聪明,只会变得越来越混乱。
人类大脑在几亿年演化中得出了看似笨拙的结论:智能必须有节律。清醒用来感知世界,睡眠用来理解世界。当一家AI公司在解决工程问题的过程中独立走向同样的结论,或许在暗示:智能有一些绕不过去的基本开销。一个从不睡觉的AI,不是更强的AI——它只是一个还没意识到自己需要睡觉的AI。


